百模大战引爆「设计比赛 千卡集群竞赛」,“中国英伟达”交卷了

作者 | 三北
编辑 | 漠影
大模型正引发一波新的AI算力荒,从此前的芯片紧缺,上升为AI算力集群级的饥渴症。
根据产业链消息,参数可能仅30亿的Sora用4200-10500块H100训练了1个月;最新出炉的Llama 3 8B和70B的训练需要24000多块H100组成的集群;据称有1.8万亿参数的GPT-4是在10000-25000张A100上完成了训练……
OpenAI、Meta等都在用数千卡、甚至万卡串联,满足不断攀升的大模型训练需求,也给了我国大模型企业一本可参考的算力账。
然而,多位GPU算力集群业内人士告诉智东西,当下我国智能算力处于严重的供不应求状态。在GPU全球稀缺背景下,单卡性能已相对没那么重要,通过集群互联实现整体算力的最大化,成为解决AI算力荒的必要路径。
政策也已经紧锣密鼓地下发。4月24日,北京市经济和信息化局、北京市通信管理局印发《北京市算力基础设施建设实施方案(2024—2027年)》,方案提出,规划建设支撑万亿级参数大模型训练需求的超大规模智算集群,并对采购自主可控GPU芯片开展智能算力服务的企业予以支持。
产业这边的动作也没有落后。国内的头部算力厂商都已加速布局大规模智算集群,比如云服务巨头华为云打造了贵安、乌兰察布、芜湖3大AI云算力中心,头部AI芯片公司摩尔线程过去四个月也已在南京、北京亦庄和北京密云完成3座全国产千卡智算中心的落地,助国产大模型产业发展提速。
大模型产业发展对智算中心提出什么新要求?国内大规模智算中心建设的真实情况如何?如何让拔地而起的千卡甚至万卡集群实现从“建起来”到“用起来”的跨越?本文试图从摩尔线程等公司的实践,对这些问题进行探讨。
一、从Sora到Llama 3,千卡集群成百模大战标配
自2024年Sora、Claude 3、Llama 3等爆火模型推出以来,大模型的智能涌现态势不减反增,推动国内大模型厂家加速追赶,对AI算力的需求也持续升级。
国产大模型玩家无论是要持续攀登Scaling Law(规模定律)高峰,还是走行业大模型的捷径,都迫切需要更大规模算力;同时大模型向多模态方向发展,需要处理包括文本、图像、声音等多种类型的数据,亟需全功能的GPU;而行业大模型甚至需要算力厂商充当起“全栈式生态服务平台”角色,服务大模型落地的“最后一公里”。
在这些多样化新需求驱动下,将芯片系统组合起来的新型千卡智算中心,成为满足大模型产业落地的重要抓手,也成为大国AI较量的标配新基建。
产业先锋已经纷纷展开行动,国内头部AI芯片公司摩尔线程在过去四个月里加速布局了三座千卡算力集群,通过自家夸娥(KUAE)智算中心解决方案为大模型打造智算底座,开箱即用,助大模型企业解决大规模GPU算力的建设和运营管理问题。
基于夸娥打造的智算中心已经初见落地成效。目前,摩尔线程支持包括Llama、GLM、Aquila、Baichuan、GPT、Bloom、玉言等各类主流大模型的训练和微调。基于摩尔线程夸娥千卡集群,70B到130B参数的大模型训练,线性加速比均可达到91%,算力利用率基本保持不变。
以2000亿训练数据量为例,智源研究院700亿参数Aquila2可在33天完成训练;1300亿参数规模的模型可在56天完成训练。此外,摩尔线程夸娥千卡集群支持长时间连续稳定运行,支持断点续训,异步Checkpoint少于2分钟。
从传统的“重硬轻软”走向“软硬一体化”,成为这批新智算集群的普遍特点。摩尔线程夸娥就是一个软硬一体化的全栈解决方案,包括基础设施、集群管理平台及模型服务,据称可全方位降低传统算力建设、应用开发和运维运营平台搭建的时间成本。
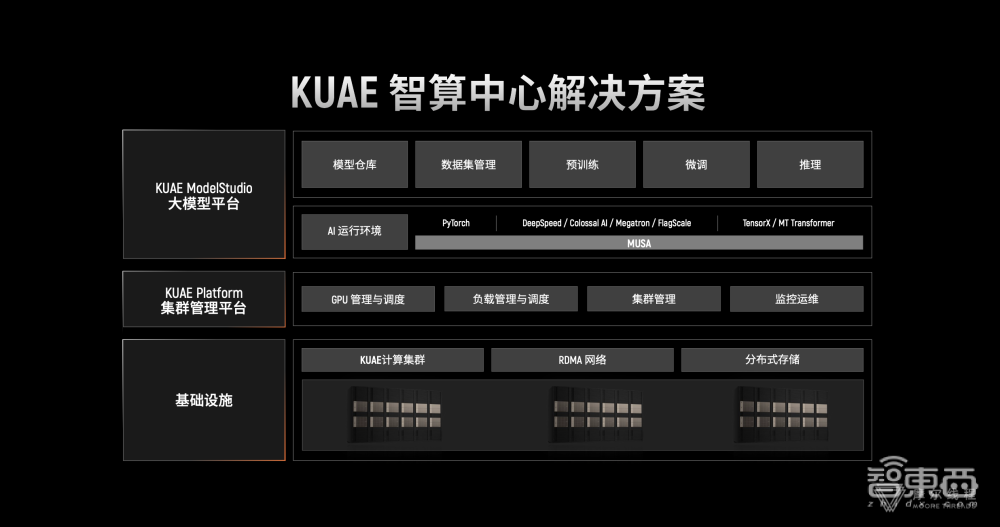
▲夸娥(KUAE)智算中心解决方案架构
基础设施:包含夸娥计算集群、RDMA网络与分布式存储。摩尔线程夸娥千卡模型训练平台,建设周期只需30天,支持千亿参数模型的预训练、微调和推理,可实现高达91%的千卡集群性能扩展系数。基于MTT S4000和双路8卡GPU服务器MCCX D800,摩尔线程夸娥集群支持从单机多卡到多机多卡,从单卡到千卡集群的无缝扩展,未来将推出更大规模的集群,以满足更大规模的大模型训练需求。
KUAE Platform集群管理平台:用于AI大模型训练、分布式图形渲染、流媒体处理和科学计算的软硬件一体化平台,深度集成全功能GPU计算、网络和存储,提供高可靠、高算力服务。通过该平台,用户可灵活管理多数据中心、多集群算力资源,集成多维度运维监控、告警和日志系统,帮助智算中心实现运维自动化。
KUAE ModelStudio模型服务:覆盖大模型预训练、微调和推理全流程,支持所有主流开源大模型。通过摩尔线程MUSIFY开发工具,可以轻松复用CUDA应用生态,内置的容器化解决方案,则可实现API一键部署。该平台意在提供大模型生命周期管理,通过简洁、易操作的交互界面,用户可按需组织工作流,大幅降低大模型的使用门槛。

▲夸娥(KUAE)智算中心解决方案支持端到端一体化交付
二、从“建起来”到“用起来”,夸娥突破4道难关
过去一年,我国千P级智算中心的智算基建布局集中爆发,根据工信部发布数据,截至2023年10月我国算力规模超300EFLOPS,智能算力占比高达35%。然而,国内的千卡智算中心仍处于发展初期,面临严峻挑战。
多位智算业内人士告诉智东西,我国智算中心建设既面临算力供应链问题,同时大规模内网互联、存储高速吞吐、模型优化服务、平台生态服务等技术因素也造成智算平台建设的技术瓶颈。
摩尔线程相关负责人谈道,集群建设是一个系统性复杂工程,从GPU显卡到服务器,最后把它组成集群,这里面包括了硬件的网络、存储、软件,再到大模型调度,是一个全栈式的工程,要真正把它做好,需要一个端到端的交钥匙方案。
从客户角度来讲,他们对千卡集群的算力利用率、稳定性、可扩展性和兼容性的需求最为突出。这也成为千卡集群建设要迈过的四道难关,摩尔线程为此做足了准备。
1、软硬协同,算力利用率提升超50%
算力利用率(MFU)是衡量智算中心能力的一个核心指标。即便是OpenAI在早期也面临MFU瓶颈,根据公开资料,其MFU在GPT-3训练阶段仅为21.3%,近79%的算力都被浪费了。
摩尔线程采用软硬协同设计、端到端的并行策略,使得综合调优下算力利用率(MFU)提升幅度超过50%。夸娥通过集群通讯库算法、网络拓扑、硬件规格合理设计和配置,优化集群匹配度;技术上,夸娥集群通讯算法网络拓扑综合利用了MTLink和PCIe,使得通讯性能提升一倍。
2、从芯片出厂开始,保证稳定可靠性
对于分布式训练而言,一张卡坏了,整个训练都会停掉。对于一个大规模集群来说,例如千卡甚至更大的集群,卡坏的概率会更高。所以,在做千卡集群或者更大规模集群时,它对整个集群的可靠性要求会更高。
摩尔线程从卡的出厂开始保证算力质量,做了很多严格的测试;开发了集群系统监控和诊断工具,帮助筛选和快速定位到有问题的卡和服务器,可以自动恢复和硬件替换;做了checkpoint加速,写的时间从10分钟降到秒级,读的速度从40分钟降到2分钟;判断训练异常,系统自动重新拉起。
3、提高可扩展性,线性加速比达91%
算力集群规模达到千卡,更是一个可扩展性的挑战。夸娥支持包括DeepSpeed、Megatron-DeepSpeed、Colossal-AI、FlagScale在内的业界主流分布式框架,并融合了多种并行算法策略,包括数据并行、张量并行、流水线并行和ZeRO,且针对高效通信计算并行和Flash Attention做了额外优化。
同时,夸娥结合了摩尔线程显卡硬件能力,以软硬一体的方式,做了系统级优化,包括从硬件、软件再到集群,外加云的全栈,不是单点突破,是一种全局综合方案,从而使得线性加速比达到91%。
4、零成本CUDA代码移植,兼容多个主流大模型
基于摩尔线程代码移植Musify工具,可快速将现有的主流迁移至MUSA,零成本完成CUDA代码自动移植,之后用户短时间内即可完成热点分析和针对性优化,大大缩短迁移优化的周期。此外,借助摩尔线程元计算统一系统架构MUSA,用户可以复用PyTorch开源社区的大量模型算子,降低开发成本。
与此同时,摩尔线程开源的MT Pytorch可以支持多种模型的推理,覆盖CV、NLP、语音等多个领域,能够运行典型的大模型分布式多卡推理,也可以支持单机多卡与多机多卡的分布式训练。利用数据并行、模型并行以及ZERO等分布式训练技术,MT PyTorch还可以完成简单基础模型以及典型Transformer结构的NLP语言模型的训练。

▲夸娥(KUAE)智算中心解决方案八大优势
总的来说,传统的计算模式在大模型时代面临着多重难点,只有长期投入并加强架构创新、软硬结合、场景结合、兼容协同等举措,才能够让智算集群完成从“建起来”到“用起来”的跨越。
三、国产大模型的超车时刻,“中国英伟达”交卷
打破英伟达对AI的垄断,国内外玩家都进入了一个“交卷”时刻。
在国外,我们看到亚马逊、微软、谷歌都已推出了面向大模型的AI定制芯片,对英伟达芯片进行部分替代,从而保证自家大模型持续可迭代和落地。
在国内,华为、摩尔线程、寒武纪、海光等头部AI芯片厂商,软硬件生态也已初具规模,技术架构自成一体,且已拥有集群能力和落地场景;同时多家AI芯片创企也在推动产品落地和量产,抢占大模型市场。
在备受关注的国产GPU领域,摩尔线程作为“中国英伟达”的主力选手,也已经打造了全栈AI方面的护城河。以全功能GPU为算力底座,摩尔线程夸娥提供从卡(MTT S4000)、服务器(MCCX D800)到千卡集群(K1、K2、K3)的完整智算产品组合,通过软硬一体化的服务,将成为大模型企业的最佳选择之一。
近日,摩尔线程正与无问芯穹联合推进基于夸娥千卡集群的“MT-infini-3B”合作大模型实训,目前性能已在同规模模型中跻身前列。无问芯穹联合创始人兼CEO夏立雪表示:“经无问芯穹Infini-AI平台实训与联合优化工作验证,摩尔线程夸娥千卡智算集群在精度、性能、易用性和算力利用率上均有优异表现,且在实训中实现了长时间稳定训练不中断,已可以为千亿参数级别大模型训练提供持续高效的高性能算力支持。之后我们会把这一合作模型在Infini-AI上开放给大家使用。”
随着今年“AI+”首次被写入两会工作报告,AI算力成为新质生产力的重要引擎,国产大模型进入关键的超车时刻。业内人士告诉智东西,今年大模型会出现一个拐点,同时也是国产AI芯片的分水岭,强者越强,弱者愈弱。
摩尔线程自2022年起就成立云计算团队,设定了建设千卡集群的大方向。在当时A100等算力紧张的背景下,摩尔线程作为在功能上唯一对标英伟达的国产GPU企业,在具备云的全栈能力后,构建基于全功能GPU的国产千卡智算集群,成为了国内赛道“第一批吃螃蟹的人”。随着大模型的爆发,摩尔线程夸娥智算中心解决方案已经完成从0到1的建设,有望成为国产大模型发展的重要引擎助力。
结语:国产大模型跨越时,千卡集群打造加速度
从ChatGPT到Sora,大模型之战已经愈演愈烈,国产大模型迫切需要加速追赶跨甚至超越,这催生了市场对更大规模、更高性能的计算资源的迫切需求,也推动计算中心的架构及运营模式进行更新换代。
千卡集群、万卡集群是满足AI算力需求的抓手,这一理念已逐渐深入人心。然而这种大规模智算集群的隐形壁垒越来越高,要求算力厂家在芯片、调优、通信及系统性开发和管理等多方面下功夫,从而真正跑出大模型产业发展的加速度。
相关热词搜索:百模大战引爆「设计比赛 千卡集群竞赛」,“中国英伟达”交卷了上一篇: 【文化中国行】老街区生活的变与不变








